Je vais présenter l’application d’un fine-tuning sur un modèle pour un projet d’école d’analyse d’images et prédictions des race de chiens.
Si vous avez des doutes sur ce qu’est le fine-tuning ou si vous souhaitez vous rafraîchir la mémoire : Qu’est-ce que le fine-tuning ?
Pour des raisons de meilleure compréhension, je vais me concentrer uniquement sur les parties importantes relatives à l’application du fine-tuning sur un modèle pré-entraîné. Les autres parties du code, qui ne seront pas détaillées ici, concernent : les imports (Sklearn, mlxtend, TensorFlow, etc.), le chargement des données ( Dog Breed Identification | Kaggle ) et les tests du modèle.
Le fine-tuning intervient principalement lors de la création du modèle pré-entraîné et de son entraînement sur nos données spécifiques.
1 - Création du modèle
Le modèle choisi est MobileNetV2, un modèle pré-entraîné reconnu pour sa légèreté et ses performances en reconnaissance d’images. Ce choix est particulièrement adapté à mon projet, qui consiste en une analyse d’images. Le modèle sera ensuite adapté à notre problème spécifique grâce au fine-tuning, ce qui permettra d’affiner ses poids pré-entraînés pour mieux reconnaître les caractéristiques propres à nos données.
base = MobileNetV2(
input_shape=(224, 224, 3),
weights="imagenet",
include_top=False,
pooling=None
)
2 - Fine-tuning partiel
Pour adapter un modèle pré-entraîné à un nouveau jeu de données, il est courant de réaliser un fine-tuning partiel. Cela signifie que certaines couches du modèle pré-entraîné restent gelées (leurs poids ne changent pas) tandis que d’autres sont entraînables afin d’apprendre des caractéristiques spécifiques à nos données.
Dans ce projet, la base du MobileNetV2 est définie comme entraînable, mais nous gelons environ 20 % des premières couches. L’objectif est de préserver les caractéristiques générales déjà apprises par le modèle (comme les contours, textures, formes de base) tout en permettant au reste du réseau de s’adapter aux spécificités de nos images.
base.trainable = True
fine_tune_ratio = 0.8
fine_tune_at = int(len(base.layers) * fine_tune_ratio)
for layer in base.layers[:fine_tune_at]:
layer.trainable = False
3 - Tête de classification
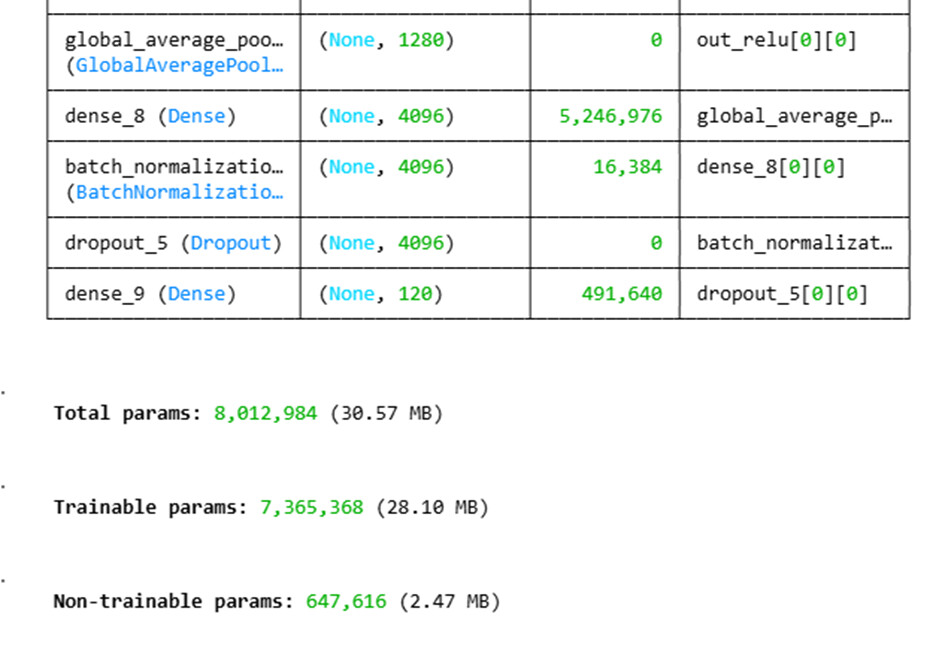
Après la base pré-entraînée, il faut ajouter une tête de classification personnalisée qui transformera les caractéristiques extraites par MobileNetV2 en prédictions pour notre problème (ici, la classification de races de chiens). Le code suivant illustre cette étape :
x = GlobalAveragePooling2D()(base.output)
x = Dense(4096, activation="relu")(x)
x = BatchNormalization()(x)
x = Dropout(0.4)(x)
outputs = Dense(120, activation="softmax")(x)
4 - Modèle final
Une fois la tête de classification ajoutée, le modèle complet peut être défini :
model = Model(
inputs=base.input,
outputs=outputs,
name="dog_breed_model_finetuned"
)
# --- Compilation (LR réduit pour fine-tuning) ---
model.compile(
optimizer=AdamW(
learning_rate=1e-5,
weight_decay=1e-4
),
loss="categorical_crossentropy",
metrics=["accuracy"]
)
5 - Entraînement
Lors de l’entraînement, certaines techniques sont utilisées pour optimiser les performances et éviter l’overfitting :
-
ReduceLROnPlateau : réduit automatiquement le learning rate si la performance sur la validation stagne, permettant au modèle de continuer à s’améliorer.
-
EarlyStopping : arrête l’entraînement si la performance sur la validation ne s’améliore plus pendant un certain nombre d’époques, évitant ainsi un surapprentissage inutile.
# Réduction automatique du LR si stagnation
reduce_lr = ReduceLROnPlateau(
monitor="val_accuracy",
factor=0.5,
patience=2,
verbose=1,
min_lr=1e-6
)
# Early stopping pour éviter overfitting
early_stop = EarlyStopping(
monitor="val_accuracy",
patience=5,
restore_best_weights=True,
verbose=1
)
Warm-up
Le warm-up est une phase initiale d’entraînement durant laquelle seules certaines parties du modèle sont mises à jour. Généralement, on entraîne uniquement la tête de classification, tandis que la base pré-entraînée (backbone) reste gelée.
Cette étape permet au modèle de s’adapter progressivement à notre jeu de données avant de débloquer le fine-tuning complet, ce qui limite les risques de déstabiliser les poids pré-entraînés et améliore la stabilité de l’entraînement.
# backbone gelé
base.trainable = False
model.compile(
optimizer=AdamW(learning_rate=1e-4, weight_decay=1e-4),
loss="categorical_crossentropy",
metrics=["accuracy"]
)
EPOCHS_HEAD = 20
history_head = model.fit(
train_gen,
validation_data=val_gen,
epochs=EPOCHS_HEAD,
steps_per_epoch=STEPS,
validation_steps=VAL_STEPS,
callbacks=callbacks,
verbose=1
)
Backbone
Le backbone d’un réseau de neurones est la partie principale du modèle chargée d’extraire les caractéristiques (features) d’une image.
Dans le cas d’un modèle pré-entraîné comme MobileNetV2, le backbone contient toutes les couches convolutives qui détectent des motifs simples (bords, textures) jusqu’aux motifs complexes (formes et structures spécifiques). Ces caractéristiques sont ensuite utilisées par la tête de classification pour produire les prédictions finales.
# dégel partiel déjà défini dans la création du modèle
base.trainable = True
fine_tune_ratio = 0.8
fine_tune_at = int(len(base.layers) * fine_tune_ratio)
for layer in base.layers[:fine_tune_at]:
layer.trainable = False
# Recompiler avec LR plus faible pour fine-tuning
model.compile(
optimizer=AdamW(learning_rate=1e-5, weight_decay=1e-4),
loss="categorical_crossentropy",
metrics=["accuracy"]
)
FINE_TUNE_EPOCHS = 10
history_finetune = model.fit(
train_gen,
validation_data=val_gen,
epochs=FINE_TUNE_EPOCHS,
steps_per_epoch=STEPS,
validation_steps=VAL_STEPS,
callbacks=callbacks,
verbose=1
)
6 - Conclusion
Le résultat de mon modèle après l’entraînement :
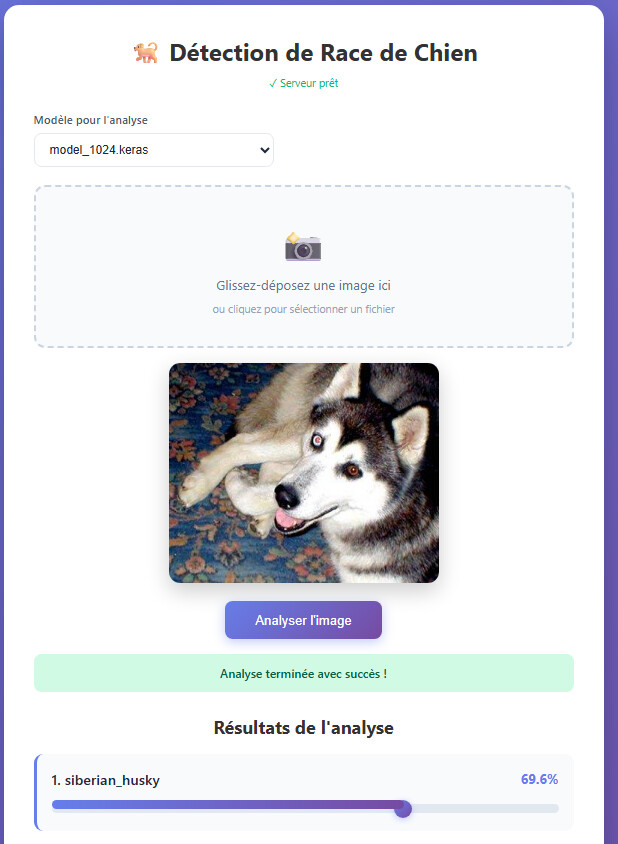
Le résultat des analyses est influencé par la durée d’entraînement et par les données utilisées. J’ai laissé mon modèle s’entraîner pendant 15 minutes (ÉPOCH 6), mais cela dépend fortement du modèle choisi, du jeu de données et de la puissance de la machine.