Imaginez pouvoir poser n’importe quelle question sur la documentation de votre entreprise, vos bases de connaissances internes ou vos archives, et obtenir des réponses précises et contextualisées instantanément. C’est exactement ce que le Retrieval Augmented Generation (RAG) rend possible ! Fini les LLM qui « hallucinent » ou qui ignorent vos données propriétaires. Le RAG combine intelligemment la puissance de recherche sémantique et la génération de texte pour créer un assistant IA qui maîtrise parfaitement VOS données. Dans cet article, nous allons construire ensemble un système RAG production-ready avec Spring AI qui transformera vos documents en véritable mine d’or conversationnelle.
Le RAG combine deux approches puissantes :
- Retrieval : Recherche d’informations pertinentes dans une base de connaissances
- Generation : Génération de réponses contextualisées par un LLM
Cette approche permet d’enrichir les réponses des IA avec des données privées ou récentes, sans nécessiter de réentraînement coûteux.
Architecture de notre solution
Un système RAG effectue principalement les actions suivantes :
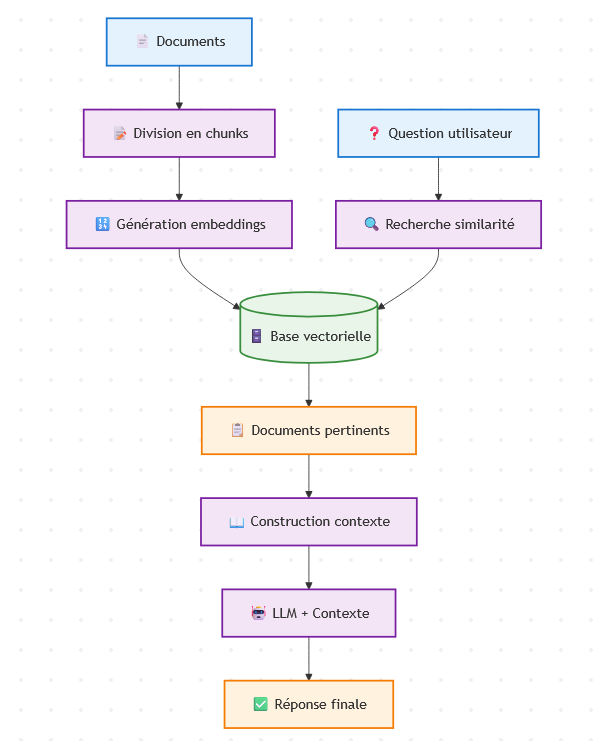
Voici le schéma RAG simplifié traduit en points avec des puces :
Architecture RAG : Flux en 2 phases
Phase 1 : Indexation des documents
 Documents sources (PDF, texte, etc.)
Documents sources (PDF, texte, etc.) Division en chunks (découpage en petits segments)
Division en chunks (découpage en petits segments) Génération d’embeddings (transformation en vecteurs)
Génération d’embeddings (transformation en vecteurs) Stockage en base vectorielle (sauvegarde pour recherche)
Stockage en base vectorielle (sauvegarde pour recherche)
Phase 2 : Recherche et génération
 Question utilisateur (requête en langage naturel)
Question utilisateur (requête en langage naturel) Recherche par similarité (trouve les chunks pertinents)
Recherche par similarité (trouve les chunks pertinents) Récupération des documents pertinents (sélection des meilleurs résultats)
Récupération des documents pertinents (sélection des meilleurs résultats) Construction du contexte (assemblage des informations trouvées)
Construction du contexte (assemblage des informations trouvées) LLM + Contexte (génération avec les données spécifiques)
LLM + Contexte (génération avec les données spécifiques) Réponse finale (réponse enrichie et contextualisée
Réponse finale (réponse enrichie et contextualisée
Solutions pour chaque étape (non exhaustif)
Solutions d’Embedding
Cloud/API
- OpenAI Embeddings (text-embedding-ada-002, text-embedding-3-small/large)
- Azure OpenAI Embeddings (version Microsoft d’OpenAI)
Open Source / Self-hosted
- Sentence Transformers (all-MiniLM-L6-v2, all-mpnet-base-v2)
- BGE Embeddings (BAAI/bge-large-en-v1.5)
- Multilingual-E5 (support multilingue)
Solutions de Stockage Vectoriel
Self-hosted
- Chroma (simple, intégration Python native)
- Qdrant (Rust, très performant, Docker-friendly)
- Milvus (scalable, production-ready)
Bases relationnelles avec extensions
- pgvector (PostgreSQL + vecteurs)
- OpenSearch (fork Elasticsearch avec support vectoriel)
En mémoire (dev/test)
- SimpleVectorStore (Spring AI, parfait pour débuter)
Solutions LLM
Cloud/API Premium
- OpenAI (ex. GPT-4o, GPT-4-turbo, GPT-3.5-turbo)
- Anthropic Claude
- Google Gemini (Gemini Pro, Gemini Ultra)
- Azure OpenAI (GPT dans l’écosystème Microsoft)
Cloud/API Accessibles
- Groq (ex. Llama)
- Hugging Face Inference (API pour tous les modèles HF)
Open Source (self-hosted)
- Llama (Meta, excellent rapport qualité/prix)
- Mixtral 8x7B (Mistral AI, très performant)
- Alpaca (Stanford, instruction-following)
Solutions On-Premise
- Ollama (déploiement local ultra-simple)
- LM Studio (interface graphique pour modèles locaux)
- vLLM (serving optimisé pour la production)
- TensorRT-LLM (NVIDIA, optimisé GPU)
Dans le prochain sujet, nous allons détailler l’implémentation avec la couche Spring AI du framework Spring.