Le découpage en chunks est essentiel pour que les modèles d’IA comprennent correctement un texte. Les modèles d’embedding réalisent ce travail afin de faciliter la conservation du contexte, permettant ainsi à la machine de fournir des réponses plus pertinentes et contextualisées. Grâce à ces chunks, il devient possible de réaliser des calculs de similarité cosinus, des recherches par similarité, du RAG (Retrieval-Augmented Generation) et d’autres applications avancées.
Un mauvais choix de techniques de découpage peut vous mettre dans des situations où votre modèle va mal répondre, halluciner, oublier du contexte, mettre plus de temps à donner une réponse, et même entraîner un coût élevé lié à l’utilisation d’un LLM.
Aujourd’hui je vais vous parler un petit peu plus des méthodes de découpage et à quoi elles servent, pour que vous puissiez avoir de bons modèles RAG dans votre entreprise.
Types de chunks :
Simple chunking
Les stratégies de découpage simple sont faciles à appliquer, mais elles peuvent avoir des contraintes. La technique utilisée consiste à transformer le texte en chunks d’une taille prédéterminée, souvent mesurée en jetons ou en caractères.
Les problèmes rencontrés sont les ruptures abruptes du texte, parce que la limitation de caractères peut interrompre le texte au milieu des phrases ou même des mots. Une taille de chunk prédéterminée ne respecte pas toujours la sémantique de la phrase ou du mot utilisé.
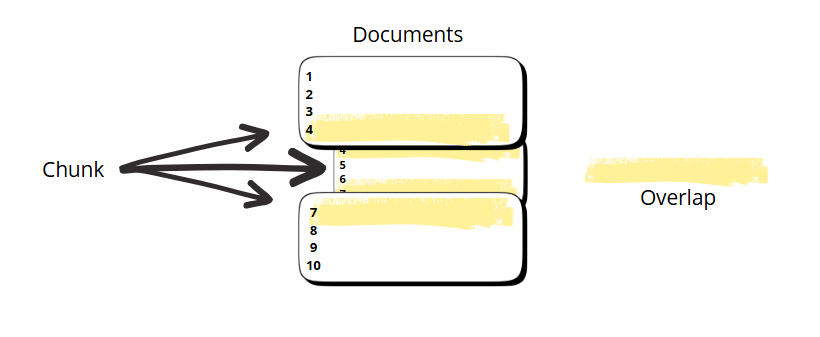
Une solution pour ce genre de problème est l’overlap, qui consiste à faire commencer le prochain chunk à partir de la fin du précédent. Il sert à préserver le contexte sémantique lorsqu’un texte est découpé en segments indépendants (par exemple pour de l’indexation, du RAG, ou du traitement NLP).
Autrement dit :
-
chaque chunk doit être compréhensible seul ou quasi seul ;
-
l’overlap doit répéter une portion significative de sens, pas des mots fonctionnels isolés.
Recursive chunking
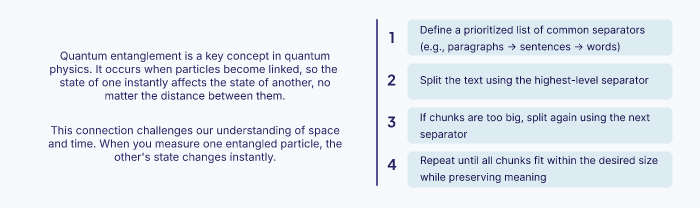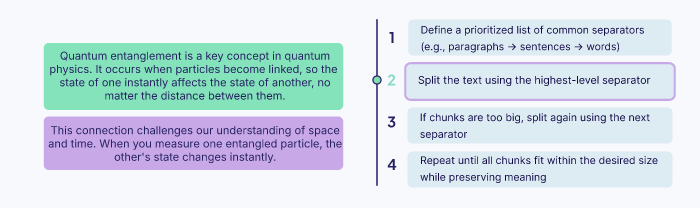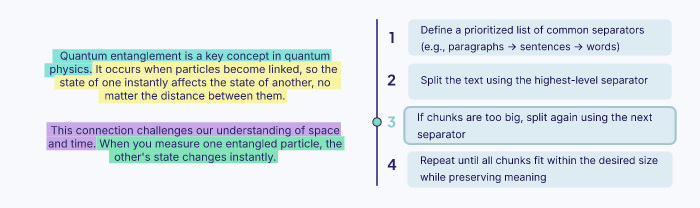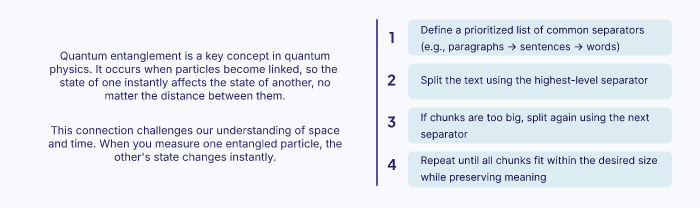
Le découpage récursif divise le texte à l’aide des séparateurs courants, comme par exemple un saut de ligne simple ou un double, les points finaux, etc pour diviser le texte selon son séparateur. Si un segment est encore trop long, l’algorithme va alors appliquer récursivement le séparateur suivant à ce segment
L’idée et de découper de la meilleure façon possible, pour avoir des segments cours et faciles à comprendre sans couper des parties importantes ou perdre des contextes. Cette méthode s’adapte à la structure du document, l’idée est d’éviter les coupages bruts et s’assure que les chunks maintien leur structure d’origine.
Document-based chunking
L’idée de se baser sur le document pour découper est d’analyser le format du document (un Markdown, HTML, PDF, code de programmation, etc.) et d’appliquer des méthodes qui respectent la logique du format présenté.
C’est-à-dire appliquer une division selon le type de document, ce qui paraît le plus logique. LangChain et LlamaIndex proposent tous les deux des outils de segmentation spécialisés pour différents types de documents.
Pour donner quelques exemples : pour le HTML, la division est souvent définie par les balises (<div>,<section> , etc.), alors que pour un PDF ça va être divisé par en-têtes, paragraphes, tableaux, etc.

Il existe aussi des techniques plus complexes, comme la Semantic Chunking (ou Context-Aware Chunking). Au lieu de s’appuyer sur le nombre de caractères ou la structure du document, cette technique divise le texte en fonction de sa similarité sémantique.
Ça veut dire qu’elle fait une analyse par similarité, une comparaison des plongements lexicaux pour détecter les points de rupture sémantique (les endroits où le sujet change), et crée de nouveaux chunks entre ces points de rupture.

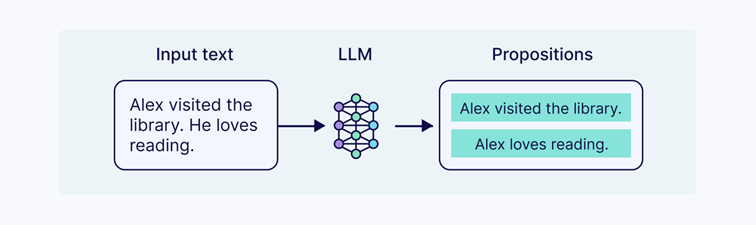
Il y a d’autres solutions comme le découpage en segments basé sur un modèle de langage (LLM), qui utilise un modèle de langage étendu pour déterminer comment segmenter le texte. Au lieu de partir sur des règles fixes ou des scores de similarité vectoriels, le LLM traite le document et génère des segments sémantiquement cohérents, en y ajoutant du contexte, des résumés ou d’autres informations.
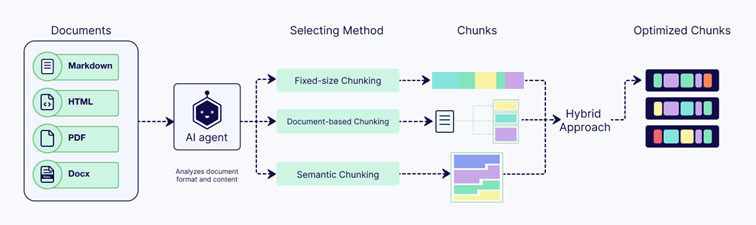
Ou même le « Agentic Chunking », qui va utiliser un agent IA pour décider dynamiquement comment segmenter le contenu de votre document. Il analyse le document en tenant compte de la structure, de la densité et du contenu, puis choisit la stratégie de découpage optimale ou une combinaison de stratégies afin d’enrichir les segments avec des métadonnées pour une recherche plus performante.
Il existe encore d’autres techniques de découpage très intéressantes. Chacune dépend de la complexité de votre projet et de la manière dont vous voulez créer les chunks pour obtenir, bien sûr, le meilleur résultat possible. À vous de chercher et de profiter des technologies disponibles.