Dans mes précédents articles, j’ai expliqué comment créer un RAG avec Python et avec N8N. Pour stocker les données et permettre des recherches intelligentes, nous avons utilisé Supabase, qui offre la possibilité de gérer des vecteurs dans sa base de données.
Mais qu’est-ce qu’une base de données vectorielle ?
Une base de données vectorielle est un type de base de données spécialement conçu pour stocker, indexer et rechercher des vecteurs numériques. Ces vecteurs sont souvent générés par des modèles d’IA ou de machine learning et permettent de représenter des entités complexes comme du texte, des images ou de l’audio.
C’est quoi la différence avec une base de données classique ?
Les bases de données classiques sont optimisées pour des recherches exactes et des opérations comme les filtres ou les jointures. Elles répondent très bien aux questions du type « quelles sont les commandes du client X ? ».
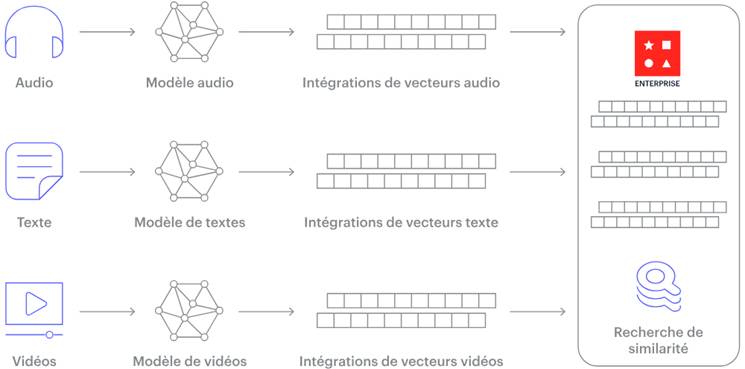
Les bases vectorielles, elles, sont conçues pour rechercher des objets similaires dans des espaces multidimensionnels. Plutôt que de chercher une correspondance exacte, elles trouvent ce qui est proche dans l’espace vectoriel, ce qui permet par exemple de retrouver des textes, images ou sons qui se ressemblent sur le plan sémantique.
Pourquoi des vecteurs ?
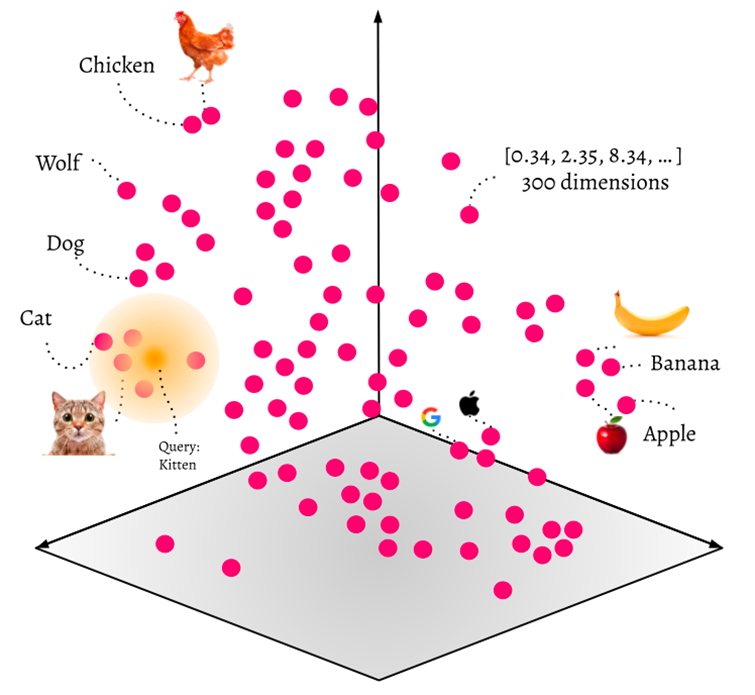
Chaque vecteur est une représentation numérique multidimensionnelle d’un objet.
- Un texte comme « le chat mignon » peut être transformé en un vecteur de 512 dimensions.
- Une image peut être représentée par un vecteur de 1024 dimensions.
Ces vecteurs capturent la sémantique ou les caractéristiques de l’objet. Plus deux vecteurs sont proches dans l’espace vectoriel, plus les objets associés sont similaires.
Pour retrouver ces vecteurs dans une base de données, l’IA utilise généralement une recherche par similarité, qui consiste à identifier les vecteurs les plus proches du vecteur de requête selon une métrique donnée. La recherche par similarité repose souvent sur des algorithmes approximatifs, qui privilégient la rapidité et la scalabilité au détriment d’une précision parfaite.
Pour rester performantes sur de grands volumes de données, les bases de données vectorielles s’appuient sur des structures d’indexation spécifiques (comme HNSW ou IVF), qui permettent de trouver rapidement les vecteurs les plus proches sans parcourir l’ensemble de la base.
Pourquoi est-elle importante dans le développement ?
Les modèles d’IA ne retrouvent rien tout seuls. Un modèle produit des vecteurs et n’a pas de mémoire persistante structurée. La base vectorielle est justement le composant qui transforme les sorties des modèles en un système exploitable. Sans une base vectorielle, votre modèle perd une grande partie de ses capacités, comme la mémoire longue, le RAG ou même la recherche sémantique.
Exemple dans une vraie base de données (Supabase)
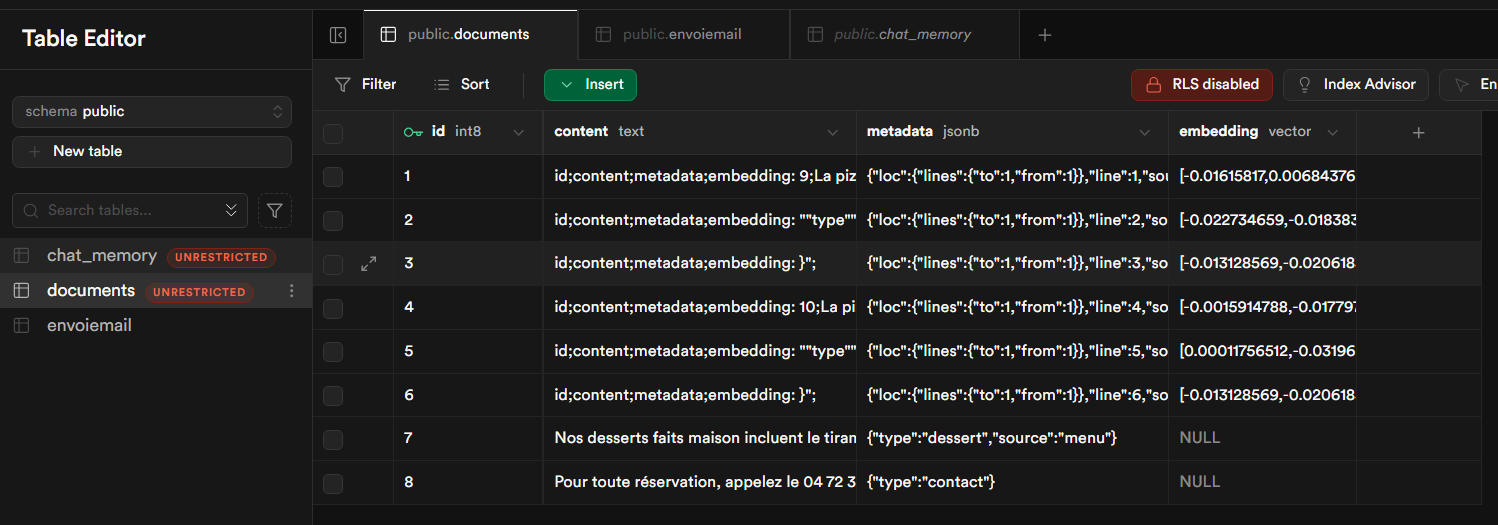
Ici, nous pouvons observer la table “documents”. Chaque enregistrement de cette table contient plusieurs champs essentiels :
-
id : l’identifiant unique du document. Il permet de retrouver rapidement chaque document dans la base.
-
content : le contenu principal du document. C’est généralement le texte que l’on souhaite analyser ou interroger.
-
metadata : des informations supplémentaires sur le document, comme l’auteur, la date de création, ou tout autre attribut pertinent pour le contexte.
-
embedding : une représentation vectorielle du contenu du document.
Ce modèle de base de données a été utilisé pour créer un RAG (Retrieval-Augmented Generation) avec n8n, permettant de combiner génération de texte et recherche intelligente dans vos données. Pour en savoir plus, vous pouvez consulter ce tutoriel : Créer un RAG avec n8n.
Conclusion
Le choix d’une base de données vectorielle dépend de plusieurs critères. D’abord, le volume de données et les performances attendues. Ensuite, les capacités d’indexation et de recherche jouent un rôle clé pour garantir rapidité et précision.
Il existe plusieurs bases adaptées aux cas d’usage IA, RAG et à la recherche sémantique. Parmi les plus utilisées, on retrouve Supabase, Pinecone, Weaviate, Milvus ou encore Qdrant.
Il n’existe donc pas de base vectorielle universelle : le bon choix dépend avant tout du contexte, des contraintes techniques et des objectifs du projet.